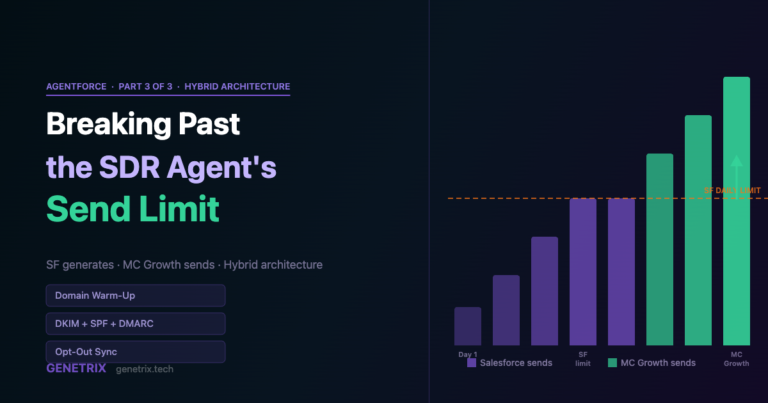
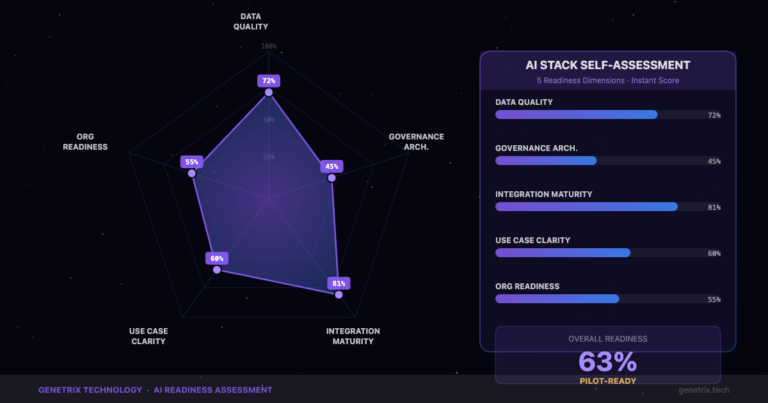
Understanding the Challenge
The challenge is to find the best option for agents to summarize or extract data from files in Salesforce, and there are multiple approaches to consider, including Document AI, RAG, and CAG.
Each approach has its limitations, such as the need for separate prompts for different file types and the ability to only work with PDFs.
Document AI Approach
Document AI is a promising approach, but it is not without its challenges, such as the need to understand how much variety a document AI model can cope with in terms of file types and the best way to retrieve the chunks related to a document in the future.
Comparison of Approaches
A comparison of the approaches reveals that Document AI is a more efficient approach for handling multiple file types, but it requires careful consideration of the model’s limitations and the retrieval of processed document chunks.
The root cause of the challenge is the need to find an approach that can efficiently handle multiple file types and provide accurate summarization or extraction of data.
Step-by-Step Solution
To implement the Document AI approach, follow these steps:
document_ai_example.js
const documentAi = require('document-ai');
const fileBuffer = fs.readFileSync('file.pdf');
const documentAiResult = documentAi.process(fileBuffer);
const extractedData = documentAiResult.extractedData;
Best Practices
To ensure the best results with the Document AI approach, follow these best practices:
Checklist
- Use a robust document AI model that can handle multiple file types
- Carefully consider the retrieval of processed document chunks
- Use a reliable way to limit the search to the related record
- Test the approach with different file types and sizes
- Monitor the performance of the document AI model
Frequently Asked Questions
Here are some frequently asked questions about the Document AI approach:
What is the best way to handle multiple file types with Document AI?
The best way to handle multiple file types with Document AI is to use a robust model that can handle different file types and sizes.
How do I retrieve the chunks related to a document in the future?
You can retrieve the chunks related to a document in the future by using a reliable way to limit the search to the related record.
What are the limitations of the Document AI approach?
The limitations of the Document AI approach include the need to understand how much variety a document AI model can cope with in terms of file types and the best way to retrieve the chunks related to a document in the future.
How do I test the Document AI approach with different file types and sizes?
You can test the Document AI approach with different file types and sizes by using a test dataset that includes different file types and sizes.
Need help shipping this in production?
Genetrix builds and untangles Salesforce Marketing Cloud and Agentforce setups for teams that want it done right the first time. If anything in this post sounds familiar, talk to us before it ships.